
Frequently Asked Question
Can a threaded rod with a welded nut be substituted for a bolt with a forged head?
When a threaded rod with a nut is substituted for a bolt with a forged head, two issues come into play. When in-house mechanical testing was performed by Portland Bolt on headed bolts versus rods with a nut, both from the identical lots of steel, the rod with a nut developed up to 12% less strength than the comparable headed bolt. The reason for this reduction in strength on the rod with nut is that the stress area at the junction of the rod and nut (which is substituting for the forged bolt head) is significantly reduced. Because the minor diameter (root) of the threads is significantly less than the full-size diameter of the unthreaded shank on a headed bolt, the rod with nut often breaks at a much lower strength than a headed bolt. More importantly, even if the rod with nut does develop enough strength to meet the specification, it will often break at the junction of the nut which is acting as the head of the bolt when wedge tested per ASTM F606. For this reason, technically a rod with a nut in lieu of a headed bolt will frequently fail mechanical testing because the head (nut in this case) comes off before the bolt breaks in the body or threaded section of the fastener which constitutes an automatic failure.
We often see fastener distributors and manufacturers without forging capabilities talking customers into switching from a headed bolt to a rod with a nut since they are unable to provide the forged product that was engineered into the structure. We see this most frequently with regard to headed anchor bolts. Making the decision to switch from a bolt with a forged head to a rod with a nut should always be approved the Engineer of Record to prevent any liability in making such a substitution should a failure of the fasteners occur.
Wedge Testing per ASTM F606
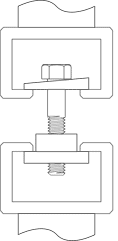
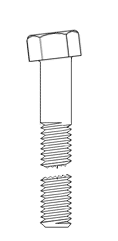
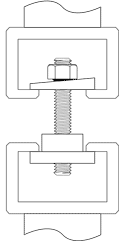
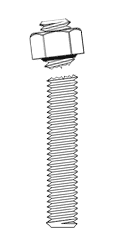
Note: Wedge testing as shown above is required to obtain mechanical properties for most ASTM high strength fasteners. A greater difference was found for high-strength fasteners than mild steel fasteners during Portland Bolt in-house testing of headed bolts versus rods with a nut. The reduced cross-sectional area at the junction of the nut as compared to a bolt with a forged head caused the fasteners with a nut acting as a bolt head to break at lower strengths than the bolts with forged heads. Additionally, the high strength rods with a nut acting as a head broke just below the nut which would automatically constitute a failure since the wedge test requires the bolt to break either in the body of the bolt or in the threaded portion, not at the junction of the head.

Years ago, we tested threaded rods because we didn’t have headed bolts. During the test, the same thing happened: the bolt failed due to the nut. The solution we implemented was to use a double nut, ensuring that the bolt would fail just as it would with a headed bolt.
The author provides a rationale for the 12% reduction attributed to thereduced surface area resulting from the presence of threads. However, it is worth noting that this disparity is already considered during the design phase through an adjustment in the tensile strength, applicable to both N-type and X-type bolts.
Thank you sharring
We’ve had a few instances where the bolt head snapped off causing catastrophic failure. Never happened in the nut-end of the bolt. Root cause was stress corrossion cracking which developed at the head. Microscopy of new bolt revealed cracks attibutable to manufacturing defects. We’re considering threaded rod at the moment, quatliy-controlling every bolt head isn’t practicable.
I have 48mm Dia bolts with washer nut and embedded in concrete 25mpa with small 5mm thick me plates at ends acting as head nut will it fail enough embedment length as per rod Dia provided please guide
@Jeevan- We are sorry, but we are unable to answer this question. You will need to contact an engineer familiar with your project.
Would 12% have mattered in a bridge build? On say a 1 3/4 inch threaded steel PT rod? And would you happen to know how far in inches you could stretch a 25 foot long 1 3/4 inch threaded PT ROD? I read over 1 inch closer to 2. That seemed rather unbelievable to me. Clearly I don’t know squat about it. The formula I found doesn’t make sense. I completely understand if you ignore me.
@Barbara- It is hard to say if a 12% difference would make a difference in your application. As for the amount of stretch, in 25 feet, I think an inch or two is reasonable, but I do not have any hard data to back that up.
What is your opinion on why many distributors are walking away from headed / forged bolt products and trying to convince their customers to move away from headed bolt products. Is there a lack of headed bolt products available for distributors or manufacturers to procure? Does no one stock headed anchor bolt products that can be cut and threaded to specification? Is there a large cost difference between headed bolts and rods with nuts welded making it uneconomical for distributors / manufacturers to want to source headed bolts?
@Mike- This has been a problem for us for quite some time. Many distributors or manufacturers to not have access to hot forged product, so they try and push a rod with a nut as an equivalent, which is of course not entirely true. Hot forging does require special equipment that many rod shops do not possess. Headed bolts are usually a bit less expensive, but it will depend on the specifics of the nee; size, grade, quantity, etc. Portland Bolt has several hot forgers and can make specials in a reasonably short time frame. Additionally, we stock several common headed anchor bolt sizes in both plain and galvanized.
These comments seem to refer to static strength, fatigue might be more important. The stud will have more elastic stretch energy so will lose less load with time and it also does not have the small rad under the bolt head to provide a fatigue start point.
Whatever is the right answer it is good to see a bolting company providing an area for customers to comment and share ideas.
It appears that the test with a wedge induces a moment on the bolt that hastens failure as opposed to a straight tensile pull. AISC formulas account for the root diameter so it seems that when one specifies a threaded rod we would get the published capacities in straight tension with a threaded rod. Is this test applicable to to how we load an embedded anchor?
@Landon- The wedge under the head does not hasten failure, it simply acts to evaluate the integrity of the head and the ductility of the material. The bolts should fracture at the same point and in the threads regardless of whether they are tested with or without a wedge. Now, if we were testing a threaded rod without a head, then the wedge would hasten failure, but those are instead tested without a wedge.
I would like to see the math on this. In the comments, it appears that the headed bolt and the threaded rod were compared using nominal specifications, e.g. a three-quarter inch bolt vs. three-quarter inch threaded rod.
But, what is the comparison in psi?
*
This article shows that it is an error to simply replace a specified headed bolt with threaded rod of the same nominal diameter. The article also says a change must be engineer approved.
*
What I want to know is this: If a contractor prefers working with threaded rod, what adjustments do I make?
@Robert- We no longer have those specific test results, as they were performed many years ago. What we are trying to do in this article is to highlight our heading capabilities and simply let the end user know that if the engineer has specified headed bolts, they should use caution before simply substituting a threaded rod, as it is not necessarily equal. As for your last question, it depends. If the bolt is in shear or straight tension, the difference between the headed bolt and the rod may be negligible. However if there are angled or moment forces at play, the headed bolt will be superior and if you’d like to substitute a rod, you may need to play with the design to make sure you don’t get yourself in trouble.
What about the exposed end of an anchor rod at the base plate? Why would a plate washer and nut at the embedded end be any diiferent?
@David Sammons- The testing we performed was in the lab as per ASTM F606. In an actual end use application embedded in concrete, we do not have any test data to reference.
Can you tell me the shear strength of threaded rod with a nut. I have job that is attaching anchors in trees. The spec calls for threaded rod so that the tree will grow around the rod. I need to attach fixtures that will hang on the rods. I need a 10,000 lbs shear. The hanger will have a 1/2 ” sleeve around the rod with a walsh against the tree and the hanger against the washer, tightened with a washer, and lock nut.
Thanks
@Steve- It will depend which grade of all thread you are using. Assuming A307A mild steel, you would need 3/4-10 all thread rod to achieve 10,000lbs of shear. If you were to move up to A193B7 all thread rod, you could reduce your diameter to 1/2-13.
How much can a grade 8 all thread. Take before it pulled in half
@Jessie – Grade 8 all thread, or any grade 8 fastener will have a minimum tensile strength of 150,000psi. To calculate the specific tensile strength of your size of all thread rod, you will need to multiply 150,000 by the tensile stress area of your diameter. Those values can be found on our website in the Technical Information area under Thread Pitch Chart.
It is my understanding, while very rare and probably custom, that an upset rod would yield similar results to the headed anchor. Correct?
@Ryan – It might, it would largely depend on the application and dimensions of the upset rod/bolts in question.
John, a smooth-sided anchor BOLT embedded in concrete works differently to an embedded rebar. It is preferable to use a BOLT since the head ‘grabs’ the concrete deep within, rather than spreading the bond along its length. Failure of the concrete in this case is closer to the surface, which is undesirable. Also, the smooth side of the bolt allows it to ‘stretch’ all the way down to the head, and thus be correctly torqued.
This test is all well and good, but when a threaded rod is embedded in concrete, I would think it would more securely “bond” with the concrete along the length of the threads and distribute the tensile load better than a headed anchor bolt with a smooth shaft, which would only resist forces at the head. But this is just my intuitive thoughts of the situation — maybe someone can comment and let me know for sure. I know that is at least how rebar works though.
@John – The concern here is in substituting one for the other. When a rod with nut is substituted for a headed bolt, the concern is that the rod/nut may not perform as well as the headed bolt. At the junction of the nut with threads, the minor diameter is smaller than at the junction of the forged head/shank. When these two combinations are tested in a lab, the forged head is far superior to the rod/nut. A fastener will always fail at it’s weakest point, by substituting the rod/nut for a headed bolt, you are possibly moving that point from the threads on the top to the junction on the bottom. That may create problems and is a decision that an engineer should make.
Will it help if the junction of the nut and the rod be tack welded. It might compensate for the 12% reduction in strength.
@Rodel Minlay – Tack welding shouldn’t make a difference in this case. In fact, most of the rods with nuts that are substituted for headed bolts are tack-welded by default. The real reduction in ultimate tensile strength in a rod with a nut stems from the fact that the tensile stress area on the threaded portion of the rod is the minor diameter of the thread, whereas the tensile stress area of a headed bolt is the full shank diameter.